
你真的了解组织诊断中的数据分析吗?
在组织诊断中,除了上期介绍诊断模型的应用(《组织诊断这么火,可你了解组织诊断模型的开发吗?》),另外一项更为重要的议题是数据分析,不同的模型对分析数据的类型与数据间的路径关系假设呈现较大的差异,如B-L模型(Burke & Litwin)、组织智能模型是组织的近似表示。
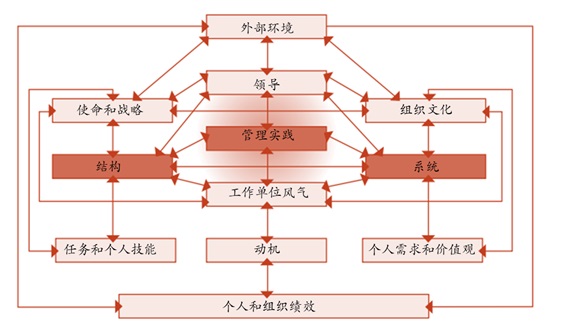
Burke& Litwin Model
B-L模型提供了一个评估组织和环境维度的框架,这些维度是成功变革的关键,它展示了如何将这些维度与因果关系相关联以实现绩效变化。外部环境的变化导致组织内部“转型”因素的变化——其使命和战略、组织文化和领导力。
因为如果发生变化,它们将对整个组织及其员工产生影响。这些转型因素的变化导致组织内部“事务性”因素的变化——组织的结构、系统、管理实践和风气。这些是更具操作性的因素,其中的变化可能会或不会对整个组织产生影响,而变革和事务性因素的变化共同影响动机,进而影响个人和组织的绩效。该模型描述了12个组织变量(包含7-s模型的7个变量)及其之间的关系。每个变量相互作用,其中任何一个变量的变化最终都会影响其他变量。这不仅有助于解释组织如何运作,还有助于解释如何改变它们。
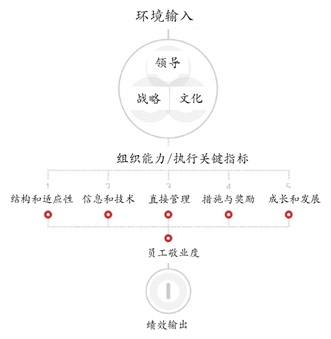
Organizational Intelligence Model
组织智能模型描述了一个自上而下的因果链,对因果关系做出了一些尝试性的假设。模型上部的变量,例如环境输入,从外部影响组织。在组织内部,战略驱动力(即领导、策略和文化)影响代表组织能力和执行力的关键指标。这些包括组织的结构和适应性、信息和技术、直接管理人员的素质、措施和奖励、成长和发展机会。这五个关键指标直接影响员工敬业度,进而影响绩效产出变量(即主要指标是推动员工参与和表现的主要因素)。最后,绩效输出变量影响环境输入变量,反之亦然。这些变量之间存在着相互关系,相对于开放系统理论,这是一个反馈性回路。
以上两种模型都对原因和有效性做出了尝试性的假设。在图形形式中,这些模型被称为路径图,因为它们描述了变量之间的关系网络(Hunter & Gerbing)。为了检验诊断模型的有效性,使用了因果建模研究范式(Falletta & Combs)。因果建模过程可以估计变量之间关系的方向和这些关系的大小(Williams & James in Greenberg)。而在组织健康指数(Organizational Health Index)模型中,对数据的应用则更偏向于采用维度聚类,对总体因变量的解释程度来设定系数和解释实际现象。
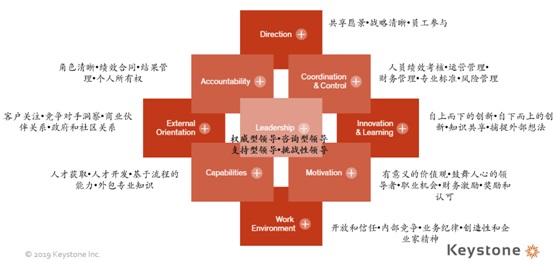
OHI模型
因而在实际的数据分析应用中,更多采用维度分析、指数化的数据分析手段。
基于数据分析应用场景的多样性和复杂性,依据实际情况我们需要有效识别出数据应用的模型边界,这就要求具备一般性的数据搜集流程规范和对数据分析手段有宏观上的功能实现辨识。
首先对于采集数据,一般性分为六个步骤:
1、确定研究目的(Research Purpose and Objectives)——并由目的制定详细的目标。
2、研究设计(ResearchDesign):通过对模型和数据的讨论,分析我们希望如何使用我们的证据进行推断的计划(King et al)。
3、总体抽样程序(Population and Sampling Procedure):确保所有部门和工作级别的工作人员都能参与本研究所用的各种数据收集方法。
4、数据采集(Data Gathering)数据收集方法包括:
(1)访谈(Interviews):半结构式访谈由一名调查人员询问一组预定的问题组成,访谈由时间表指导。因为访谈一般是深度的,采访时间从45分钟到1小时不等。所有的参与者都被简要地解释了研究的目的、使用的模型以及研究人员打算如何诊断。这有助于从参与者那里得到更好的输入和更多的想法。
(2)调查问卷(Survey Questionnaires)一般采用李克特量表。
(3)观察(Observation)对所选择的社会环境中的事件、行为和人工制品的系统描述(Marshall and Rossman)。
(4)标杆经验导入法。即从外部找标杆,借鉴知名成功企业的做法,再将企业的实际情况加以结合,得出适合本企业的能力素质模型。
5、数据分析(Data Analysis):定性数据采用内容分析法,按照模型进行聚类。定量数据采用更精确的数据。
6、质量保证(Quality assurance):确保数据真实是建立可信度的最重要因素之一,在定性方法中,数据三角测量有助于比较和交叉检验在不同时间和通过不同方法得到的信息的一致性(Patton, 2002),特别是对ODQ(Organizational Diagnosis Questionnaires,组织诊断问卷),确保较低级别的工作人员能理解ODQ,并能够提供有效和正确的答案,从而提高ODQ的有效性,数据质量保证要从完整性、一致性、准确性和及时性进行把控,可提高数据的(跨)场景解释力,Lincoln和Guba认为可转移性是指定性研究的结果可以概括或转移到其他情境或环境中的程度。
其实在数据搜集的过程中,亦是在反向论证数据分析手段可行性,即数据搜集的前提是我们基本已经清楚接下来所要使用的分析技术手段,因为这决定搜集数据的类型和边界;但是单一从数据的分析手段为始,再用对应数据类型去适配,接着用对应的诊断模型去适配数据类型,形成数据分析决定所需数据类型,数据类型决定接下来采用的分析模型,这样的逻辑链条颇有为数据分析而数据分析的嫌疑;因而数据搜集过程中的反向论证,即我们要实现的目的是否真的适合采取该数据分析方式,是否有必要“削足适履”去匹配单一的数据分析手段,这就要求我们能对整体的数据分析手段有一个宏观上的认识和定位,能够灵活根据实际场景去挑选合适的数据分析方法,而不是紧紧抓着单一的数据分析方法尝试去解释所有的应用场景。
对于数据分析的方法而言,从描述性分析到大数据分析,层层递进,复杂度增加,对现实的解释角度增加,大大增加了对现实的拟合度。
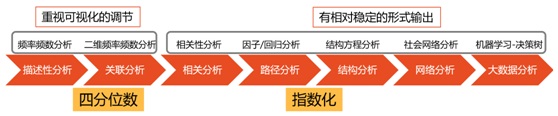
数据分析谱
数据分析在组织诊断及人力资源其他议题中应用的灵活性有助于我们发现和解释问题,而数据分析的进阶则是深化了我们对问题症结的认知,从数据分析的发展来看,呈现2个基本特征线索:
(1)平面-层级-网络的跃迁。这匹配着现实中错综复杂的变量关系,在Takanori Ugai《基于社会网络分析的组织诊断工具》书中论证网络关系在诊断模型中的应用可行性;
(2)变量强相关-弱相关的研究范式转化。面对信息流在量和种类上的急剧增速,面对特定的议题,我们已经不能有把握地说出变量间的强因果联系,而在大数据下也不必拘泥于研究变量间的因果关系,变量弱关系甚至仅存在相关性特征的提出和应用大大解放数据使用者绞尽脑汁去解释变量的劳动输出,而仅关注相关同样可以研究如何产出和改善最大化。
从宏观上了解了数据分析手段的跃迁链条,那在微观层面各种数据分析手段又会有怎样的假设前提、操作流程、可视化以及应用场景呢?下次再介绍。
本文作者:科石咨询顾问 王国峰